 Christmas Mega Sale – Enjoy Up to 50% OFF on Every Plan!
Christmas Mega Sale – Enjoy Up to 50% OFF on Every Plan! 
Robots.txt Generator
What Is a Robots.txt File?
The robots.txt file is a plain text file or set of instructions located in the root directory of a website. It provides instructions to web crawlers or search engine bots regarding which pages or sections of the site should be crawled and indexed.
How To Use Our Robots.txt Generator?
Below are the steps to use our Robots.txt Generator with a practical example.
- Enter the sitemap URL as shown below.

- Here, you have to set a crawl delay in seconds. We are taking 5 seconds here.
This parameter specifies the time gap between successive requests made to the website by web crawlers. The “No Delay” option means no specific delay is imposed.
- Now, the user is required to specify directories that should be restricted from search engine crawlers. In the provided example, the “/cart/”, “/checkout/” “/my-account/” directory is set to be disallowed.You can add or remove directories as per your
requirements.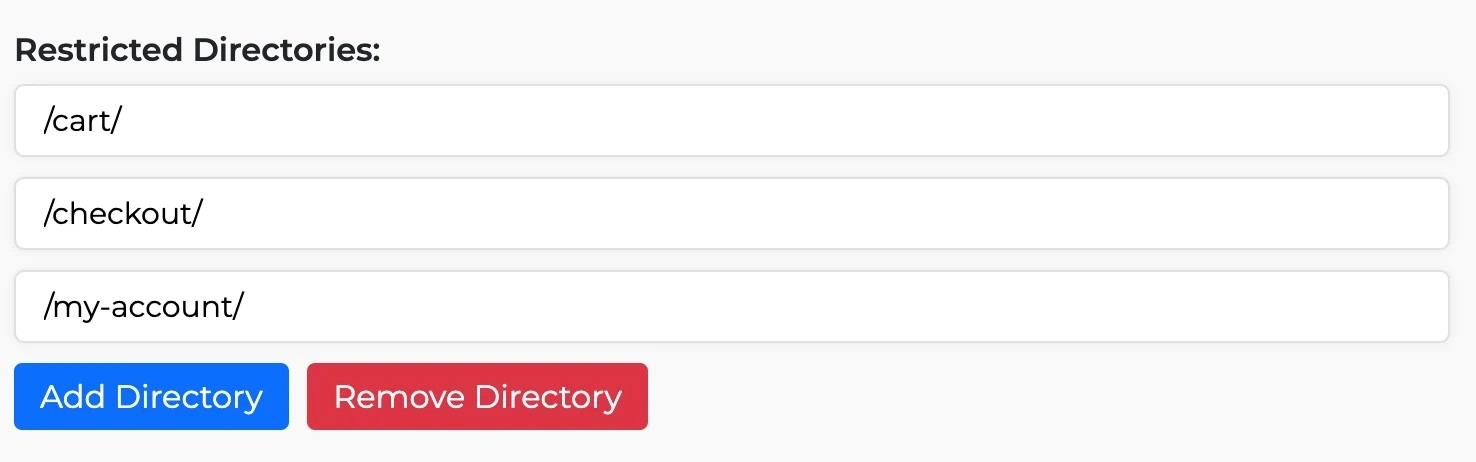
- This option determines whether the generated robots.txt file will allow or disallow all web crawlers. Here, the choice is set to “Allowed.”

- Finally, click the “Generate” button to get a live preview, and a copy will automatically download to your system.
Disallow: Crawl-delay: 5
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
Sitemap: http://w3speedup.com/sitemap.xml
How Does a Robots.txt File Work?
The working of a Robots.txt file is pretty straightforward. Simply, it tells SERPs which sections of the websites need to be crawled.
Let’s understand this with an example.
A website named “www.example.com” has given the below instructions. This states that all bots can crawl the website except “GPTBot.”
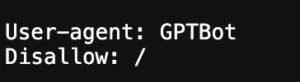
Caution: Be careful while working with the Robots.txt file because a simple mistake, like accidentally blocking Googlebot from your entire site, can be a major setback. It’s like slamming the door shut on search engines, affecting your site’s visibility. That’s why you should always double-check your directives to avoid unexpected issues.
IMPORTANT: A Robots.txt file can only provide instructions but can’t force them. Responsible bots will respect these directives and crawl only the designated areas.
However, it’s essential to acknowledge that some less scrupulous bots, such as spam or malicious web crawlers, may disregard these guidelines.
Importance of Robots.txt
- Managing site architecture
Robots.txt file plays a vital role in managing the architecture of a website. It guides the search engine bots through the most important sections of the site while excluding less critical or duplicate content.
- Prevent duplicate content issues
Do you know search engines can penalize your website for duplicate content? How to avoid this concern? Robots.txt will help as it automatically excludes certain sections or URLs.
- Protect sensitive information
Robots.txt allows website owners to prevent sensitive information, such as personal data, login pages, or administrative sections, from being indexed on SERPs.
Why Choose Our Robots Txt Generator?
| User-friendly Interface
Our tool has a user-friendly interface that allows users, even those with limited technical knowledge, to create and customize their robots.txt files easily. |
Up-to-date with the Latest Guidelines
To stay ahead, we regularly update our tool to align with the latest recommendations and changes in search engine algorithms. |
Validation and Error Prevention
Use our tool to avoid common mistakes that could negatively impact your website’s search engine rankings. |
| Customization
Our Robot.txt generator allows you to define which sections should be crawled and which ones should remain off-limits. |
Live Preview
See the real-time preview of the file before deploying them and ensure that the directives align seamlessly with your SEO strategy. |
Secure
We take your website’s safety seriously. That’s why our tool is secure and ensures your website is strong and protected from possible security problems. |
What Are The Best Practices For Robot.txt Files?
1. Ensure Clean Formatting
Separate each directive with a new line in your robots.txt file. If instructions are jumbled together, search engines might overlook them, rendering your efforts ineffective.
Avoid: User-agent: * Disallow: /admin/
Disallow: /directory/
Prefer: User-agent: *
Disallow: /admin/
Disallow: /directory/
2. Simplify with Asterisk
Use asterisks (*) to apply directives universally. Instead of listing out individual URLs, asterisk usage streamlines instructions.
3. End URLs Effectively
Use the “$” symbol to signify the end of a URL pattern. This prevents inefficient listing of individual files.
For instance,
User-agent: *
Disallow: /*.jpg$
4. Use Hash for Comments:
Insert comments with the “#” symbol. Crawlers disregard commented lines, making it an effective way to add notes for organization and readability.
5. Make different Robots.txt file for different domains
Maintain separate robots.txt files for different subdomains, as each file only influences crawling behavior within its respective subdomain.
Frequently Asked Questions (FAQs)
1. How can I check if my website has a robots.txt file?
You can check if your website has a robots.txt file by following the simple steps below.
- Type your website’s root domain in the address bar, like www.example.com.
- Extend the URL by adding “/robots.txt” to the end. So, for our example, it would be w3speedup.com/robots.txt.
- Hit Enter to load the URL.
- If a robots.txt file exists, you will see its content displayed in your browser.
- If you don’t see any .txt page or encounter a “Page Not Found” error, it means you currently don’t have a (live) robots.txt page.
2. Do I need a Robots.txt file for every subdomain?
Yes, robots.txt files are specific to each subdomain. If your website has multiple subdomains, you should have a separate robots.txt file for each to control the crawling behavior independently.
3. Why does my website need a robots.txt file?
Your website needs a robot.txt file for several reasons.
- To prevent duplicate content from appearing on SERPs.
- To specify the sitemap location.
- To prevent search engine bots from crawling certain sections of the website.
- To keep certain sections of the website private.
- To prevent overloading the servers when search engine crawlers load multiple pieces of content simultaneously.
4. How does our robots.txt generator work?
Our robots.txt generator prompts users to input their sitemap URL, specify crawl delays, identify restricted directories, and set permissions for web crawlers. Then, the tool will generate a robots.txt file based on these inputs.
Are you interested in using Schema Markup Generator or Domain Age Checker? You must give it a try, as all of our tools are free and safe to use!
